
In this blog post, we'll walk through the process of classifying movie reviews from the IMDB dataset using TensorFlow, a powerful library for machine learning and deep learning. The IMDB dataset is a popular dataset for sentiment analysis, where the goal is to classify movie reviews as positive or negative based on their text content.

What is the IMDB Dataset in TensorFlow?
The IMDB dataset in TensorFlow is a widely used dataset for sentiment analysis tasks. It is included in TensorFlow's Keras API and is designed to help users build and evaluate models for classifying movie reviews as either positive or negative. Here's a detailed overview:
Overview of the IMDB Dataset
The IMDB dataset contains 50,000 movie reviews. These reviews are divided equally into positive and negative sentiments.
Each review is represented as a sequence of integers, where each integer corresponds to a word in the review. These integers are based on a pre-defined vocabulary of the most frequent words in the dataset.
Training Set: 25,000 reviews (12,500 positive and 12,500 negative)
Test Set: 25,000 reviews (12,500 positive and 12,500 negative)
The dataset is used primarily for binary classification tasks, where the objective is to predict whether a given review is positive or negative.
It's useful for evaluating sentiment analysis algorithms and understanding the impact of various text processing and modeling techniques.
X: The review texts, encoded as sequences of integers.
y: Labels indicating sentiment, with 0 for negative reviews and 1 for positive reviews.
Prerequisites
Before we dive into the code, make sure you have the following installed:
Python
TensorFlow
NumPy
Matplotlib (optional, for visualization)
You can install TensorFlow using pip:
pip install tensorflowClassifying the IMDB dataset with TensorFlow
Classifying the IMDB dataset with TensorFlow involves building a model to predict the sentiment of movie reviews, distinguishing between positive and negative sentiments. The IMDB dataset, which includes 50,000 reviews split equally between positive and negative, is preprocessed into sequences of integers representing words. By leveraging TensorFlow's Keras API, you can efficiently load and prepare this data, apply text preprocessing techniques like padding to standardize input sizes, and construct a deep learning model. Typically, a model for this task includes embedding layers to convert word indices into dense vectors, followed by recurrent layers like LSTMs to capture sequential dependencies in the text. The model is trained on labeled data to learn patterns associated with positive and negative sentiments, and its performance is evaluated on a separate test set to ensure its effectiveness. This approach provides a robust framework for sentiment analysis and demonstrates TensorFlow's capabilities in handling natural language processing tasks.
Step 1: Import Necessary Libraries
Start by importing TensorFlow and other necessary libraries:
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
Step 2: Load and Prepare the IMDB dataset
TensorFlow’s Keras API provides a built-in method to load the IMDB dataset. It comes preprocessed with integer-encoded words.
# Load the dataset
vocab_size = 10000 # Number of words to use in the dataset
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
# Pad sequences to ensure uniform input size
max_length = 500 # Maximum length of each review
X_train = pad_sequences(X_train, maxlen=max_length)
X_test = pad_sequences(X_test, maxlen=max_length)
Output for the above code:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/stepStep 3: Build the Model
We'll use a Sequential model with an embedding layer, LSTM layer, and a dense output layer. This architecture is common for text classification tasks.
# Model architecture
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=128, input_length=max_length),
LSTM(128, return_sequences=True),
LSTM(64),
Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Step 4: Train the TensorFlow Model
Now we’ll train the model using the training data.
# Model training
history = model.fit(
X_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.2
)
Output for the above code:
Epoch 1/5
313/313 ━━━━━━━━━━━━━━━━━━━━ 640s 2s/step - accuracy: 0.6977 - loss: 0.5566 - val_accuracy: 0.8504 - val_loss: 0.3753
Epoch 2/5
313/313 ━━━━━━━━━━━━━━━━━━━━ 664s 2s/step - accuracy: 0.8874 - loss: 0.2908 - val_accuracy: 0.8712 - val_loss: 0.3276
Epoch 3/5
313/313 ━━━━━━━━━━━━━━━━━━━━ 616s 2s/step - accuracy: 0.9046 - loss: 0.2444 - val_accuracy: 0.8722 - val_loss: 0.3360
Epoch 4/5
313/313 ━━━━━━━━━━━━━━━━━━━━ 651s 2s/step - accuracy: 0.9526 - loss: 0.1337 - val_accuracy: 0.8586 - val_loss: 0.3617
Epoch 5/5
313/313 ━━━━━━━━━━━━━━━━━━━━ 649s 2s/step - accuracy: 0.9656 - loss: 0.1066 - val_accuracy: 0.8492 - val_loss: 0.4029Step 5: Evaluate the Model
After training, evaluate the model’s performance on the test data.
# Model evaluation
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.4f}')
Output for the above code:
782/782 ━━━━━━━━━━━━━━━━━━━━ 278s 355ms/step - accuracy: 0.8457 - loss: 0.4237
Test Accuracy: 0.8509Step 6: Visualize Training History
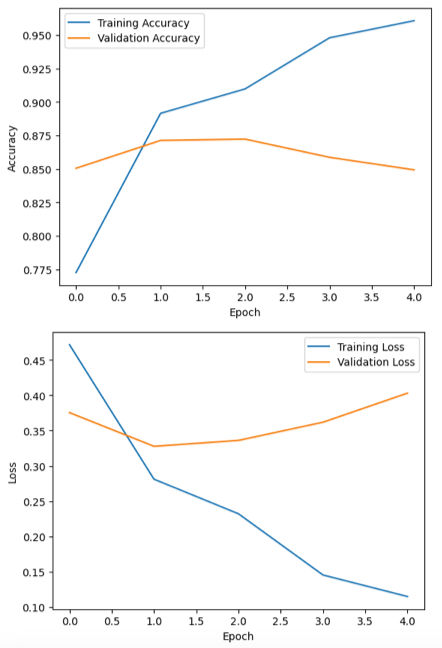
Plot the training and validation accuracy and loss to understand how well the model is learning.
# Plot model training & validation accuracy
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# Plot model training & validation loss
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Output for the above code:
Full Code for Classifying the IMDB dataset with TensorFlow
Here’s the complete code to classify the IMDB dataset with TensorFlow. This example demonstrates loading the dataset, preprocessing the data, building a model with LSTM layers, and evaluating its performance. Run this code to start building a sentiment analysis model from scratch.
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
# Load the dataset
vocab_size = 10000 # Number of words to use in the dataset
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
# Pad sequences to ensure uniform input size
max_length = 500 # Maximum length of each review
X_train = pad_sequences(X_train, maxlen=max_length)
X_test = pad_sequences(X_test, maxlen=max_length)
# Model architecture
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=128, input_length=max_length),
LSTM(128, return_sequences=True),
LSTM(64),
Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Model training
history = model.fit(
X_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.2
)
# Model evaluation
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.4f}')
# Plot model training & validation accuracy
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# Plot model training & validation loss
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Conclusion
In this guide, we explored the process of classifying the IMDB dataset using TensorFlow, focusing on sentiment analysis. We began by understanding the dataset, which contains a balanced set of 50,000 movie reviews, split evenly between positive and negative sentiments. By leveraging TensorFlow's Keras API, we demonstrated how to load and preprocess the dataset, including tokenizing and padding sequences to ensure uniform input sizes.
We built a deep learning model that incorporates an embedding layer to convert word indices into dense vectors, followed by LSTM layers to capture the sequential nature of text data. This architecture is well-suited for text classification tasks, enabling the model to learn and generalize from the patterns in the data. Training the model involved tuning it with the training dataset and evaluating its performance on a separate test set to ensure its predictive accuracy.
The provided code serves as a foundational example for sentiment analysis with TensorFlow, illustrating key concepts such as data preprocessing, model construction, and evaluation. This example can be further extended by experimenting with different model architectures, hyperparameters, and text processing techniques. Mastery of these techniques opens doors to more advanced natural language processing tasks and applications, showcasing TensorFlow's power and flexibility in the field of machine learning.
Comments