
In the digital age, data is the new gold. Every transaction, click, and social media post generates data that can provide valuable insights if analyzed effectively. Data analytics is the process of examining datasets to draw conclusions about the information they contain. Python, a versatile and powerful programming language, has emerged as a favorite tool for data analytics due to its simplicity, extensive libraries, and community support. In this blog, we'll explore the basics of data analytics with Python and demonstrate its capabilities with practical examples.

Why Python for Data Analytics?
Python has emerged as the go-to language for data analytics due to its simplicity, versatility, and robust ecosystem of libraries. Its intuitive syntax makes it accessible for beginners while being powerful enough for experts to handle complex data tasks. Libraries such as Pandas and NumPy provide efficient tools for data manipulation and numerical operations, respectively, while Matplotlib and Seaborn offer comprehensive options for data visualization. Additionally, Scikit-learn and TensorFlow cater to machine learning needs, making Python a one-stop solution for all stages of data analysis. The active community and extensive documentation further enhance its appeal, ensuring ample resources and support for users.
Ease of Learning and Use: Python’s syntax is simple and readable, making it an ideal choice for both beginners and experienced programmers.
Rich Ecosystem of Libraries: Python boasts a plethora of libraries tailored for data analytics, such as NumPy, Pandas, Matplotlib, and Scikit-learn.
Community Support: A large, active community means extensive documentation, tutorials, and forums to seek help.
Importance of Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is a critical step in the data science process, as it lays the foundation for any subsequent analysis or modeling. By thoroughly examining the data, EDA helps uncover underlying patterns, trends, and relationships that are not immediately apparent. It allows data scientists to identify anomalies, missing values, and outliers, which can significantly impact the results of any analysis. Moreover, EDA provides valuable insights into the data's structure and distribution, enabling better-informed decisions about which statistical methods or machine learning algorithms to apply. Ultimately, EDA ensures the reliability and validity of the analysis, making it an indispensable tool for any data-driven project.
Pythonic Libraries for Data Analytics
Python's prominence in data analytics is largely due to its rich ecosystem of libraries that cater to various aspects of the analytical process. Pandas is indispensable for data manipulation and analysis, offering data structures like DataFrames that make handling structured data seamless. NumPy provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. For data visualization, Matplotlib and Seaborn stand out; Matplotlib offers detailed control over plot aesthetics, while Seaborn simplifies complex visualizations with its high-level interface. Scikit-learn is a powerhouse for machine learning, featuring tools for classification, regression, clustering, and dimensionality reduction. Additionally, TensorFlow and PyTorch cater to more advanced machine learning and deep learning tasks. These libraries, backed by a robust community and extensive documentation, make Python an essential tool for data analysts and scientists.
Pandas Library in Python for Data Analytics
Pandas is a powerful library designed for data manipulation and analysis. It introduces two primary data structures: Series (one-dimensional) and DataFrame (two-dimensional), which handle and manipulate data in a variety of formats including CSV, Excel, and SQL databases. Pandas makes it easy to clean, transform, and analyze data with intuitive operations such as filtering, grouping, and merging. Its ability to handle large datasets efficiently makes it indispensable for data preprocessing and exploratory data analysis, serving as a foundation for further data science tasks.
NumPy Library in Python for Data Analytics
NumPy, short for Numerical Python, is the fundamental package for scientific computing with Python. It provides support for large multi-dimensional arrays and matrices, along with a rich collection of mathematical functions to operate on these arrays. NumPy’s powerful n-dimensional array object and broadcasting functions make complex numerical operations straightforward and efficient. It forms the base for many other scientific libraries in Python, including Pandas, and is essential for tasks requiring high-performance numerical computations.
Matplotlib Library in Python for Data Analytics
Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits. With Matplotlib, you can generate a wide range of plots including line graphs, bar charts, histograms, and scatter plots. It is highly customizable, allowing for detailed control over the appearance of plots. Matplotlib's versatility and ease of use make it a go-to library for visualizing data and conveying insights effectively.
Seaborn Library in Python for Data Analytics
Seaborn is built on top of Matplotlib and provides a high-level interface for drawing attractive and informative statistical graphics. It comes with several built-in themes and color palettes to make it easy to create aesthetically pleasing plots. Seaborn simplifies the creation of complex visualizations such as heatmaps, violin plots, and pair plots, which are often used in statistical data exploration. Its ability to handle Pandas DataFrames seamlessly allows for quick and easy visualization of data relationships and distributions.
Scikit-learn Library in Python for Data Analytics
Scikit-learn is a robust library for machine learning in Python. It provides simple and efficient tools for data mining and data analysis, built on NumPy, SciPy, and Matplotlib. Scikit-learn includes a wide range of algorithms for classification, regression, clustering, and dimensionality reduction, as well as tools for model selection and evaluation. Its consistent API and comprehensive documentation make it accessible for beginners while offering enough depth for advanced users. Scikit-learn is crucial for building predictive models and conducting sophisticated data analyses.
TensorFlow Library in Python for Data Analytics
TensorFlow is an open-source library developed by Google for numerical computation and machine learning. It allows for the creation of large-scale neural networks with many layers, known as deep learning models. TensorFlow is highly flexible and can run on multiple CPUs and GPUs, as well as mobile devices. It provides extensive tools for deploying machine learning models in production environments. TensorFlow's ecosystem includes libraries for easy model building (Keras), robust machine learning pipelines (TFX), and model deployment (TensorFlow Serving), making it a comprehensive tool for end-to-end machine learning workflows.
Getting Started with Python for Data Analytics a Practical Guide
To get started, you'll need to install Python and some essential libraries. Use the following commands to install them:

Loading the Dataset
For demonstration, we’ll use the Titanic dataset, which contains information about passengers aboard the Titanic. You can load this dataset directly from the Seaborn library.

Understanding the Data Structure
Start by getting a sense of the dataset’s structure and contents.

Handling Missing Values
Missing values can significantly affect your analysis. Identifying and handling them is crucial. You can choose to fill missing values, drop them, or use other imputation methods depending on the situation.

Univariate Analysis with Python
Univariate analysis is the simplest form of data analysis, focusing on a single variable to understand its distribution and key characteristics. Using Python, this process becomes straightforward and efficient with libraries like Pandas, Matplotlib, and Seaborn. For numerical variables, histograms and box plots are commonly used to visualize data distribution, central tendency, and dispersion. For categorical variables, bar plots effectively illustrate frequency counts. These visualizations, combined with summary statistics like mean, median, mode, and standard deviation, provide a comprehensive understanding of each variable in isolation. This foundational step in data analysis helps identify patterns, detect anomalies, and guide subsequent multivariate analyses. Univariate analysis involves examining each variable individually.

Bivariate Analysis with Python
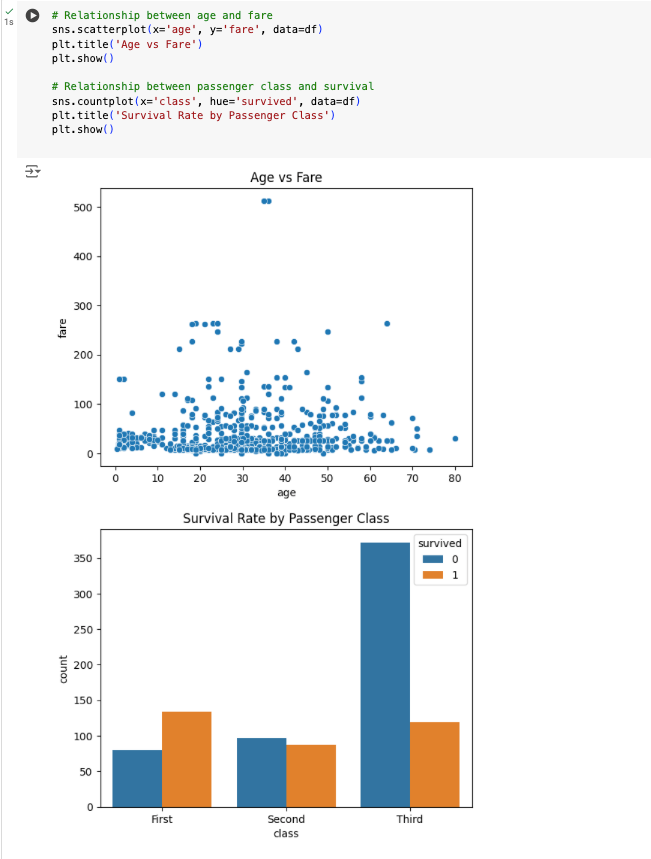
Bivariate analysis examines the relationship between two variables to uncover patterns, associations, and potential causal links. Using Python, this analysis becomes straightforward and insightful with libraries like Pandas, Seaborn, and Matplotlib. For instance, in Google Colab, you can use Seaborn’s scatterplot to visualize the relationship between two numerical variables, such as age and fare in the Titanic dataset, highlighting correlations or clusters. Additionally, categorical variables can be analyzed through countplot to explore how different categories, such as passenger class, relate to survival rates. These visualizations help in understanding the interactions between variables, leading to better-informed decisions and hypotheses for further investigation. Bivariate analysis involves exploring the relationship between two variables.

Identifying and Handling Outliers
Outlier analysis is a critical component of exploratory data analysis that involves identifying and addressing data points significantly different from the rest of the dataset. In Python, this can be efficiently achieved using libraries like Pandas, NumPy, and Seaborn. Outliers can distort statistical analyses and lead to misleading conclusions. Visual tools such as boxplots and scatter plots help in detecting these anomalies. Once identified, outliers can be managed through various methods such as removal, transformation, or capping. For instance, using the IQR (Interquartile Range) method, outliers can be clipped to a specified range to minimize their impact. Proper outlier analysis ensures the robustness and accuracy of subsequent data analyses and models.Outliers can skew your analysis and lead to incorrect conclusions.

In conclusion, exploratory Data Analysis is a crucial step in the data science workflow. It helps in understanding the data, making informed decisions, and setting the stage for further analysis and modeling. With Python’s powerful libraries like Pandas, Matplotlib, and Seaborn, conducting EDA becomes a streamlined and insightful process. By following the steps outlined in this blog, you can uncover hidden patterns, detect anomalies, and prepare your data for advanced analytics.
Comments