
Sentiment Analysis with Python: Analyzing Text from 20 Newsgroups and Movie Reviews
- Samuel Black
- Aug 17, 2024
- 6 min read
Sentiment analysis is a fascinating area of natural language processing (NLP) that involves determining the emotional tone behind a piece of text. In this blog, we'll explore sentiment analysis using Python with some built-in datasets. We’ll cover the basics of sentiment analysis, how to preprocess data, and how to implement a simple sentiment analysis model. Let's dive in!

What is Sentiment Analysis?
Sentiment analysis is a branch of natural language processing (NLP) focused on determining the emotional tone or sentiment expressed within a piece of text. The primary goal is to classify text into categories such as positive, negative, or neutral, reflecting the underlying sentiment or opinion of the writer. This analysis helps organizations and individuals understand public opinion, customer feedback, and social media conversations. By leveraging various algorithms and models, sentiment analysis can automatically process large volumes of text, providing insights that would be challenging to glean manually. This technique is widely used in fields such as marketing, customer service, and social media monitoring to gauge sentiment and make data-driven decisions.
Sentiment Analysis in Python
Sentiment analysis in Python leverages powerful libraries and tools to efficiently assess and classify the emotional tone of text. With Python’s rich ecosystem, you can easily preprocess text data, build models, and evaluate their performance. Libraries like NLTK (Natural Language Toolkit) and Scikit-learn offer built-in datasets and functionalities to streamline the analysis process. For example, NLTK provides access to various text corpora and sentiment analysis tools, while Scikit-learn enables efficient implementation of machine learning models such as Logistic Regression and Support Vector Machines. Additionally, libraries like pandas facilitate data manipulation, and visualization tools like Matplotlib and Seaborn help in interpreting model results. By combining these resources, Python makes it straightforward to perform sentiment analysis, from data preparation and model training to evaluation and visualization, making it an ideal language for NLP tasks.
Sentiment Analysis in Python Applications
Each of the following applications leverages sentiment analysis to extract meaningful insights and drive data-informed decisions in various domains:
Customer Feedback Analysis: Analyze reviews and feedback from customers to gauge satisfaction and identify areas for improvement.
Social Media Monitoring: Track and analyze sentiment on social media platforms to understand public opinion, brand perception, and emerging trends.
Market Research: Evaluate sentiment in news articles and market reports to gauge investor sentiment and market trends.
Product Reviews: Automatically classify product reviews into positive, negative, or neutral categories to help businesses understand customer experiences.
Sentiment Tracking Over Time: Monitor changes in sentiment over time to assess the impact of marketing campaigns or product updates.
Content Moderation: Identify and filter out inappropriate or harmful content based on sentiment analysis in forums or user-generated content platforms.
Political Sentiment Analysis: Analyze public sentiment regarding political events, speeches, or campaigns to gauge voter sentiment and political trends.
Customer Service Automation: Automate responses and prioritize support tickets based on the sentiment expressed in customer queries.
Brand Health Monitoring: Assess sentiment around a brand to measure brand health and address any negative perceptions swiftly.
.
Setting Up Python Environment for Sentiment Analysis
To effectively perform sentiment analysis using Python, it's essential to set up a well-organized development environment. Begin by installing Python, which serves as the foundation for your analysis. Ensure you have a recent version of Python (3.x) installed on your system. Next, you'll need to install several key libraries that facilitate data manipulation, text processing, and machine learning. Start by installing essential libraries using pip, Python's package manager. Key libraries include:
Pandas: For data manipulation and analysis. Install with pip install pandas.
Scikit-learn: Provides tools for machine learning, including preprocessing and model building. Install with pip install scikit-learn.
NLTK (Natural Language Toolkit): Useful for text processing and sentiment analysis tools. Install with pip install nltk.
Matplotlib and Seaborn: For data visualization and plotting. Install with pip install seaborn.
pip install pandas scikit-learn nltk seaborn matplotlibAfter setting up your environment, ensure you download any additional resources needed for specific libraries, such as NLTK corpora. For example, you can download NLTK datasets using nltk.download().
With your Python environment configured and libraries installed, you're ready to start performing sentiment analysis, exploring datasets, and building models. This setup will provide a solid foundation for developing and experimenting with sentiment analysis techniques.
Loading Built-in Datasets
Python offers several built-in datasets for sentiment analysis. For this blog, we'll use the following datasets:
NLTK’s Movie Review Dataset: A collection of movie reviews labeled as positive or negative.
Scikit-learn’s 20 Newsgroups Dataset: A dataset of newsgroup posts that we can use for multi-class sentiment classification.
Let's start by loading these datasets.
NLTK’s Movie Review Dataset
NLTK’s Movie Review dataset is a widely-used resource for sentiment analysis tasks. It contains a collection of movie reviews, each labeled as either positive or negative. This dataset provides a practical way to train and evaluate sentiment analysis models. Here’s how you can access and utilize the Movie Review dataset in Python:
import nltk
from nltk.corpus import movie_reviews
import pandas as pd
nltk.download('movie_reviews')
# Load the dataset
documents = [(movie_reviews.raw(fileid), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
# Create a DataFrame
df = pd.DataFrame(documents, columns=['text', 'sentiment'])
df['sentiment'] = df['sentiment'].map({'pos': 1, 'neg': 0})
print(df.head())
Output for the above code:
[nltk_data] Downloading package movie_reviews to /root/nltk_data...
[nltk_data] Unzipping corpora/movie_reviews.zip.
text sentiment
0 plot : two teen couples go to a church party ,... 0
1 the happy bastard's quick movie review \ndamn ... 0
2 it is movies like these that make a jaded movi... 0
3 " quest for camelot " is warner bros . ' firs... 0
4 synopsis : a mentally unstable man undergoing ... 0Scikit-learn’s 20 Newsgroups Dataset
Scikit-learn’s 20 Newsgroups dataset is a popular dataset for text classification tasks. It consists of approximately 20,000 newsgroup documents, categorized into 20 different newsgroups. This dataset is useful for training and evaluating text classification models and can be adapted for sentiment analysis or other NLP tasks. Here’s how you can access and utilize the 20 Newsgroups dataset in Python:
from sklearn.datasets import fetch_20newsgroups
# Load the dataset
newsgroups = fetch_20newsgroups(subset='all')
df_newsgroups = pd.DataFrame({'text': newsgroups.data, 'target': newsgroups.target})
df_newsgroups['target'] = df_newsgroups['target'].map(dict(enumerate(newsgroups.target_names)))
print(df_newsgroups.head())
Output for the above code:
text target
0 From: Mamatha Devineni Ratnam <mr47+@andrew.cm... rec.sport.hockey
1 From: mblawson@midway.ecn.uoknor.edu (Matthew ... comp.sys.ibm.pc.hardware
2 From: hilmi-er@dsv.su.se (Hilmi Eren)\nSubject... talk.politics.mideast
3 From: guyd@austin.ibm.com (Guy Dawson)\nSubjec... comp.sys.ibm.pc.hardware
4 From: Alexander Samuel McDiarmid <am2o+@andrew... comp.sys.mac.hardwarePreprocessing the Datasets in Python
Before training a model, it’s important to preprocess the text data. This typically involves:
Tokenization: Splitting text into words.
Removing stop words: Filtering out common words that do not contribute much meaning.
Vectorization: Converting text into numerical format using techniques like Bag of Words or TF-IDF.
Here's an example of preprocessing for the Movie Review dataset:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
# Tokenization and vectorization
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(df['text'])
y = df['sentiment']
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"Features shape: {X_train.shape}, Labels shape: {y_train.shape}")
Output for the above code:
Features shape: (1600, 39354), Labels shape: (1600,)Building a Sentiment Analysis Model using sklearn
We’ll use a simple machine learning model such as Logistic Regression for sentiment analysis.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Train the model
model = LogisticRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
Output for the above code:
Accuracy: 0.825
Classification Report:
precision recall f1-score support
0 0.82 0.83 0.83 199
1 0.83 0.82 0.82 201
accuracy 0.82 400
macro avg 0.83 0.83 0.82 400
weighted avg 0.83 0.82 0.82 400Visualizing the Results
Visualizations can help understand the performance of your model.
import matplotlib.pyplot as plt
import seaborn as sns
# Create a confusion matrix
from sklearn.metrics import confusion_matrix
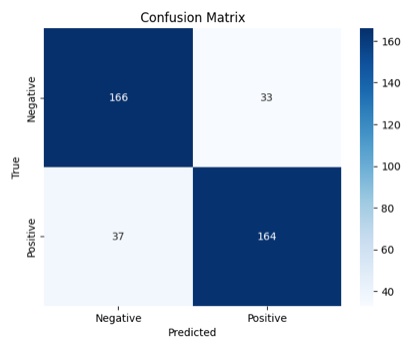
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Negative', 'Positive'], yticklabels=['Negative', 'Positive'])
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
Output for the above code:
Conclusion
In this blog, we explored the essential components of sentiment analysis using Python and built-in datasets. We began by understanding the fundamental concept of sentiment analysis and then delved into practical aspects such as data loading, preprocessing, model building, and evaluation.
We utilized NLTK’s Movie Review dataset and Scikit-learn’s 20 Newsgroups dataset to demonstrate how to perform sentiment analysis. Through preprocessing steps like tokenization and vectorization, we converted textual data into a format suitable for machine learning. We then trained a Logistic Regression model and evaluated its performance using accuracy and confusion matrix visualizations.
This process highlighted how sentiment analysis can be implemented effectively with built-in datasets, providing a strong foundation for more advanced techniques. Whether you're working on a simple sentiment analysis task or building more complex NLP applications, understanding these basics is crucial.
Feel free to apply these concepts to your projects and continue exploring the fascinating world of sentiment analysis. If you have any questions or need further assistance, don't hesitate to reach out. Happy analyzing!

Comments