
Clustering is a fundamental task in machine learning that involves grouping a set of objects so that those in the same group (or cluster) are more similar to each other than to those in other groups. It's an unsupervised learning technique widely used for exploratory data analysis, customer segmentation, anomaly detection, and more. In this blog, we'll explore the top 5 clustering algorithms you should learn in Python, highlighting their features, use cases, and implementation using popular Python libraries like scikit-learn.

What are Machine Learning clustering algorithms?
Machine Learning clustering algorithms are a subset of unsupervised learning techniques used to group similar data points into clusters. Unlike supervised learning, where the model is trained on labeled data, clustering does not require predefined labels or categories. Instead, it aims to find natural groupings in the data based on inherent similarities. These algorithms work by analyzing the features of the data points and partitioning them into clusters where points within the same cluster are more similar to each other than to those in different clusters. Clustering algorithms are widely used in various fields for tasks such as customer segmentation, pattern recognition, image analysis, and anomaly detection. Common clustering algorithms include K-Means, Hierarchical Clustering, DBSCAN, Mean Shift, and Gaussian Mixture Models, each offering unique approaches to discovering patterns in data.
1. K-Means Clustering
Overview: K-Means is one of the simplest and most popular clustering algorithms. It partitions the dataset into K distinct clusters by minimizing the sum of squared distances between data points and the centroids of the clusters.
How It Works:
Initialize K centroids randomly.
Assign each data point to the nearest centroid.
Recompute the centroids as the mean of the assigned points.
Repeat steps 2 and 3 until convergence.
Use Cases:
Market segmentation
Document clustering
Image compression
Implementation K-Means in Python
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# Generate sample data
X, = makeblobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Apply K-Means
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='x')
plt.title('K-Means Clustering')
plt.show()
Output for the above code:
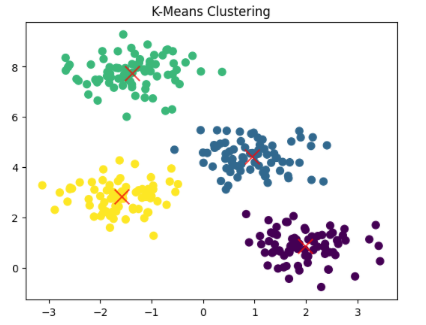
2. Hierarchical Clustering
Overview: Hierarchical clustering builds a hierarchy of clusters by either merging small clusters into larger ones (agglomerative) or splitting large clusters into smaller ones (divisive). It's particularly useful when you want a visual representation of the clustering structure through a dendrogram.
How It Works:
Start with each data point as its own cluster.
Iteratively merge the closest pair of clusters until a single cluster remains (agglomerative).
Use Cases:
Gene expression data analysis
Social network analysis
Customer segmentation
Implementation Hierarchical Clustering in Python
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
# Generate sample data
X, = makeblobs(n_samples=150, centers=3, cluster_std=0.50, random_state=0)
# Perform hierarchical clustering
Z = linkage(X, 'ward')
# Plot dendrogram
plt.figure(figsize=(10, 7))
dendrogram(Z)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Sample index')
plt.ylabel('Distance')
plt.show()
Output for the above code:
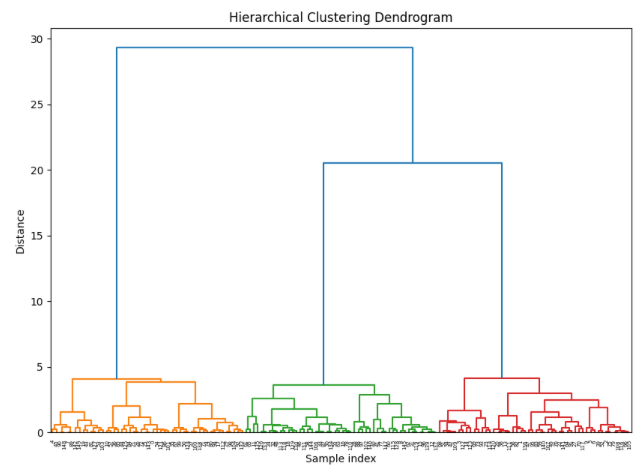
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Overview: DBSCAN is a density-based clustering algorithm that can identify clusters of varying shapes and sizes, and is particularly effective at identifying outliers or noise. It does not require specifying the number of clusters beforehand.
How It Works:
For each data point, DBSCAN identifies the points within a specified radius (ε) as its neighbors.
Points with at least a minimum number of neighbors (MinPts) are classified as core points, forming the nucleus of a cluster.
Clusters are formed by connecting core points and their neighbors, while points that don't belong to any cluster are classified as noise.
Use Cases:
Anomaly detection
Geographic data analysis
Market basket analysis
Implementation DBSCAN in Python
from sklearn.cluster import DBSCAN
import numpy as np
# Generate sample data
X, = makeblobs(n_samples=300, centers=4, cluster_std=0.50, random_state=0)
# Apply DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5)
y_dbscan = dbscan.fit_predict(X)
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_dbscan, cmap='Paired')
plt.title('DBSCAN Clustering')
plt.show()
Output for the above code:
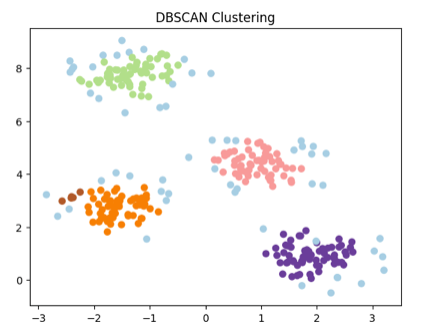
4. Mean Shift
Overview: Mean Shift is a non-parametric clustering technique that aims to discover "blobs" in a smooth density of data points. It does not require specifying the number of clusters and works by iteratively shifting data points towards the mode of the density distribution.
How It Works:
Start with an initial set of data points as candidate centroids.
Compute the mean of the points within a given bandwidth around each centroid.
Shift the centroid to the mean and repeat until convergence.
Use Cases:
Image segmentation
Object tracking
Mode estimation
Implementation Mean Shift in Python
from sklearn.cluster import MeanShift
# Generate sample data
X, = makeblobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
# Apply Mean Shift
meanshift = MeanShift(bandwidth=1)
y_meanshift = meanshift.fit_predict(X)
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_meanshift, cmap='viridis')
plt.title('Mean Shift Clustering')
plt.show()
Output for the above code:
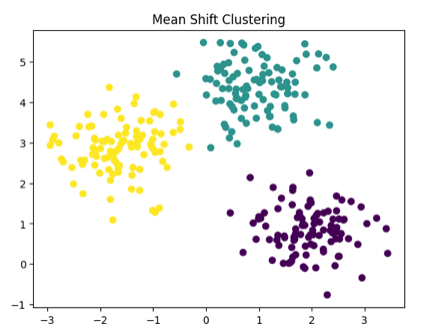
5. Gaussian Mixture Models (GMM)
Overview: Gaussian Mixture Models are a probabilistic model that assumes all the data points are generated from a mixture of several Gaussian distributions with unknown parameters. GMM is flexible in terms of cluster shape and size and can capture more complex data distributions than K-Means.
How It Works:
Assign data points to Gaussian distributions with different probabilities.
Estimate the parameters of the Gaussians (mean and covariance) using the Expectation-Maximization (EM) algorithm.
Iterate until convergence.
Use Cases:
Anomaly detection
Voice recognition
Image segmentation
Implementation Gaussian Mixture Models (GMM) in Python
from sklearn.mixture import GaussianMixture
# Generate sample data
X, = makeblobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
# Apply Gaussian Mixture Model
gmm = GaussianMixture(n_components=3)
gmm.fit(X)
y_gmm = gmm.predict(X)
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_gmm, cmap='viridis')
plt.title('Gaussian Mixture Model Clustering')
plt.show()
Output for the above code:
Conclusion
Clustering algorithms are essential tools in machine learning and data analysis, offering valuable insights by grouping data based on similarity. Each algorithm has its strengths and ideal use cases, depending on the nature of the data and the desired outcome. Python, with its rich ecosystem of libraries like scikit-learn, makes it easy to implement and experiment with these algorithms. Whether you're working on customer segmentation, anomaly detection, or image analysis, mastering these clustering techniques will undoubtedly enhance your data science skill set and open up new possibilities for data exploration and pattern discovery.
Comments