
In the world of machine learning, Support Vector Machines (SVM) are a powerful and versatile tool for classification, regression, and even outlier detection. This blog post will explore the fundamentals of SVMs and how to implement them in Python using popular libraries like Scikit-learn. By the end, you'll understand the theory behind SVMs and be equipped to apply them to your own datasets.
What is a Support Vector Machine?
Support Vector Machines are a class of supervised learning algorithms that can be used for both classification and regression tasks. The primary goal of SVM is to find the optimal hyperplane that separates the data points of different classes with the maximum margin. The margin is the distance between the hyperplane and the nearest data points from either class, known as support vectors. Key concepts in SVM's:
Hyperplane: A decision boundary that separates different classes in the feature space. A hyperplane is essentially separates data points into different classes.Imagine a line dividing two clusters of points on a graph; in higher dimensions, this line becomes a hyperplane. The goal of SVM is to find the optimal hyperplane that best distinguishes the data points. The dimension of the hyperplane depends on the number of features in the dataset.
Support Vectors: Support vectors are the data points that lie closest to the hyperplane and significantly influence its position.These points are crucial as they define the margin, the distance between the hyperplane and the nearest data points. The SVM algorithm focuses on maximizing this margin, and the support vectors play a pivotal role in achieving this objective.Even a slight shift in the position of support vectors can lead to a change in the hyperplane.
Margin: The margin is the region between the parallel hyperplanes that pass through the closest data points (support vectors) of each class.Maximizing the margin is a core principle in SVM. A wider margin generally indicates a better model as it provides a larger tolerance for unseen data points. The SVM algorithm strives to find the hyperplane that creates the largest possible margin, enhancing the model's generalization ability.
Hyperparameters and Kernels
Support Vector Machines (SVM) are highly versatile due to their use of different kernels and hyperparameters, allowing them to adapt to various data distributions and complexities. Understanding and tuning these elements can significantly impact the performance of your SVM model.
1. Kernel Function
The kernel function is a key component of SVMs that allows them to handle non-linear relationships by mapping the input features into a higher-dimensional space. This mapping enables the SVM to find a linear separating hyperplane in this new space, even if the data is not linearly separable in the original space. The choice of kernel depends on the data characteristics and the specific problem at hand.
Linear Kernel (kernel='linear'): This is the simplest kernel, often used when the data is linearly separable. It maps the input space directly without transformation.
Polynomial Kernel (kernel='poly'): This kernel maps the input features into a polynomial space. The degree of the polynomial can be specified by the degree parameter.
Radial Basis Function (RBF) Kernel (kernel='rbf'): The RBF kernel, also known as the Gaussian kernel, is one of the most popular choices. It can map the data into an infinite-dimensional space, making it highly flexible for various patterns.
Sigmoid Kernel (kernel='sigmoid'): This kernel behaves similarly to a neural network's activation function. It can be useful in specific cases but is less commonly used compared to the RBF and polynomial kernels.
2. Hyperparameters
Tuning the hyperparameters of an SVM is crucial for optimizing its performance. Some important hyperparameters include:
C (Regularization Parameter): The C parameter controls the trade-off between maximizing the margin and minimizing classification errors. A smaller C encourages a larger margin, even if it means more misclassified points. A larger C tries to classify all training examples correctly, at the cost of a smaller margin.
Gamma (gamma): This parameter defines how far the influence of a single training example reaches, affecting the shape of the decision boundary. A small gamma value means a wider influence, resulting in a smoother decision boundary. A large gamma value leads to a more complex decision boundary, which can model intricate patterns.
Degree (degree): Relevant only for the polynomial kernel, this parameter specifies the degree of the polynomial. It controls the flexibility of the decision boundary.
Coefficient 0 (coef0): Used in polynomial and sigmoid kernels, this parameter adjusts the influence of higher-order versus lower-order terms.
3. Choosing the Right Kernel and Hyperparameters
The choice of kernel and hyperparameters depends on the nature of the data and the problem you're trying to solve. Here are some general guidelines:
Start Simple: Begin with the linear kernel and a low C value to understand the basic separability of your data.
Experiment with Kernels: If the linear kernel doesn't provide good results, try more complex kernels like RBF or polynomial.
Use Grid Search and Cross-Validation: Employ techniques like grid search with cross-validation to systematically explore different combinations of hyperparameters and select the best-performing model.
Consider Computational Cost: Complex kernels and large values of C and gamma can lead to longer training times. Balance model complexity with computational resources.
Implementing SVM in Python
We'll use the popular Scikit-learn library to implement an SVM classifier. For demonstration purposes, we'll work with the Iris dataset, a classic dataset in machine learning.
Step 1: Importing Libraries
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
Step 2: Loading and Preparing the Dataset
# Load the Iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# For simplicity, we'll only use two classes and two features
X = X[y != 2, :2]
y = y[y != 2]
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 3: Training the SVM Model
# Create an SVM classifier with a linear kernel
svm_classifier = SVC(kernel='linear')
# Train the model
svm_classifier.fit(X_train, y_train)
Step 4: Making Predictions and Evaluating the Model
# Make predictions on the test set
y_pred = svm_classifier.predict(X_test)
# Evaluate the model
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Output for above code:
[[12 0]
[ 0 8]]
precision recall f1-score support
0 1.00 1.00 1.00 12
1 1.00 1.00 1.00 8
accuracy 1.00 20
macro avg 1.00 1.00 1.00 20
weighted avg 1.00 1.00 1.00 20
Step 5: Visualizing the Decision Boundary
# Visualize the decision boundary
def plot_decision_boundary(X, y, model):
h = .02 # step size in the mesh
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('SVM Decision Boundary')
plt.show()
# Plot the decision boundary
plot_decision_boundary(X_train, y_train, svm_classifier)
Output for above code:
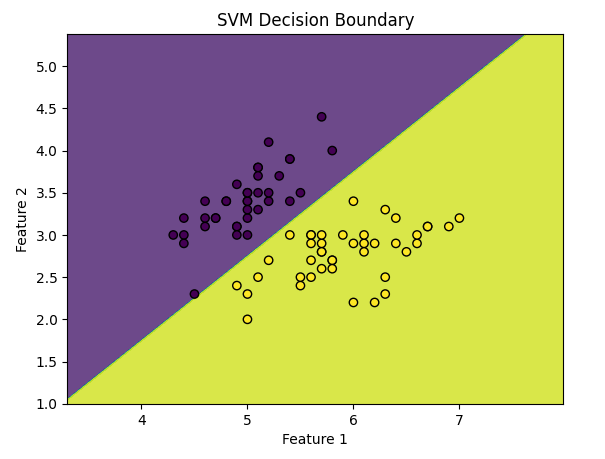
In conclusion, Support Vector Machines (SVM) are a powerful and versatile tool in the machine learning toolkit, capable of handling both linear and non-linear classification tasks. By finding the optimal hyperplane that maximizes the margin between classes, SVMs can effectively classify data points with high accuracy. The choice of kernel and the tuning of hyperparameters such as C and gamma are crucial in determining the performance of an SVM model.
The flexibility offered by different kernels allows SVMs to adapt to various data structures, from simple linear separations to complex non-linear boundaries. However, with this flexibility comes the need for careful model selection and tuning, which can be achieved through methods like cross-validation and grid search.
In practice, starting with simple models and progressively experimenting with more complex kernels and parameters can help in understanding the nature of the data and finding the best model. It's also essential to balance the model's complexity with computational efficiency, especially when working with large datasets.
In summary, SVMs are a robust and reliable method for classification and regression, offering a range of options to tailor the model to specific datasets. By understanding the underlying principles and effectively utilizing the available hyperparameters and kernels, practitioners can harness the full potential of SVMs to solve a wide array of real-world problems.
Comments